Sie treffen Entscheidungen auf Basis von Feedback. Doch was, wenn dieses Feedback nie ehrlich war?
Organisationen erheben ständig sensible Daten, um bessere Entscheidungen zu treffen: Mitarbeiterumfragen zum Arbeitsklima, Analytics zur Produktverbesserung auf Basis echter Nutzungssignale, Ad-Attribution um zu messen, welche Werbung tatsächlich zu Käufen führt. Was am Ende zählt, sind Muster und Aggregate, nicht einzelne Datenpunkte.

Trotzdem sind genau diese einzelnen Datensätze in den meisten Systemen für jeden mit dem richtigen Zugriff lesbar. Tools wie Google Forms, SurveyMonkey oder LimeSurvey speichern jede Antwort als Klartext auf einem Server. „Anonym” heißt in der Praxis, dass es kein Feld für deinen Namen gibt. Das ist alles. Server verabeiten dabei klassisch IP-Adressen, Zeitstempel, Browser-Fingerprints und speichern deine Antworten zu der Abteilung, Vertragsform. All dies ist für jeden mit System-Zugang einsehbar, sowohl für abtrünnige Mitarbeiter als auch für böswillige Angreifer.

Wie schnell „anonym” zerfällt
Ein Beispiel: Ein Ingenieurbüro mit 80 Mitarbeitenden führt eine Umfrage durch, und in der Konstruktionsabteilung arbeitet genau eine Frau. Ihre Antwort auf „Fühlen Sie sich gleichberechtigt behandelt?” ist für jeden mit Zugriff durch die Kombination von Abteilung und Geschlecht eindeutig zuordenbar.
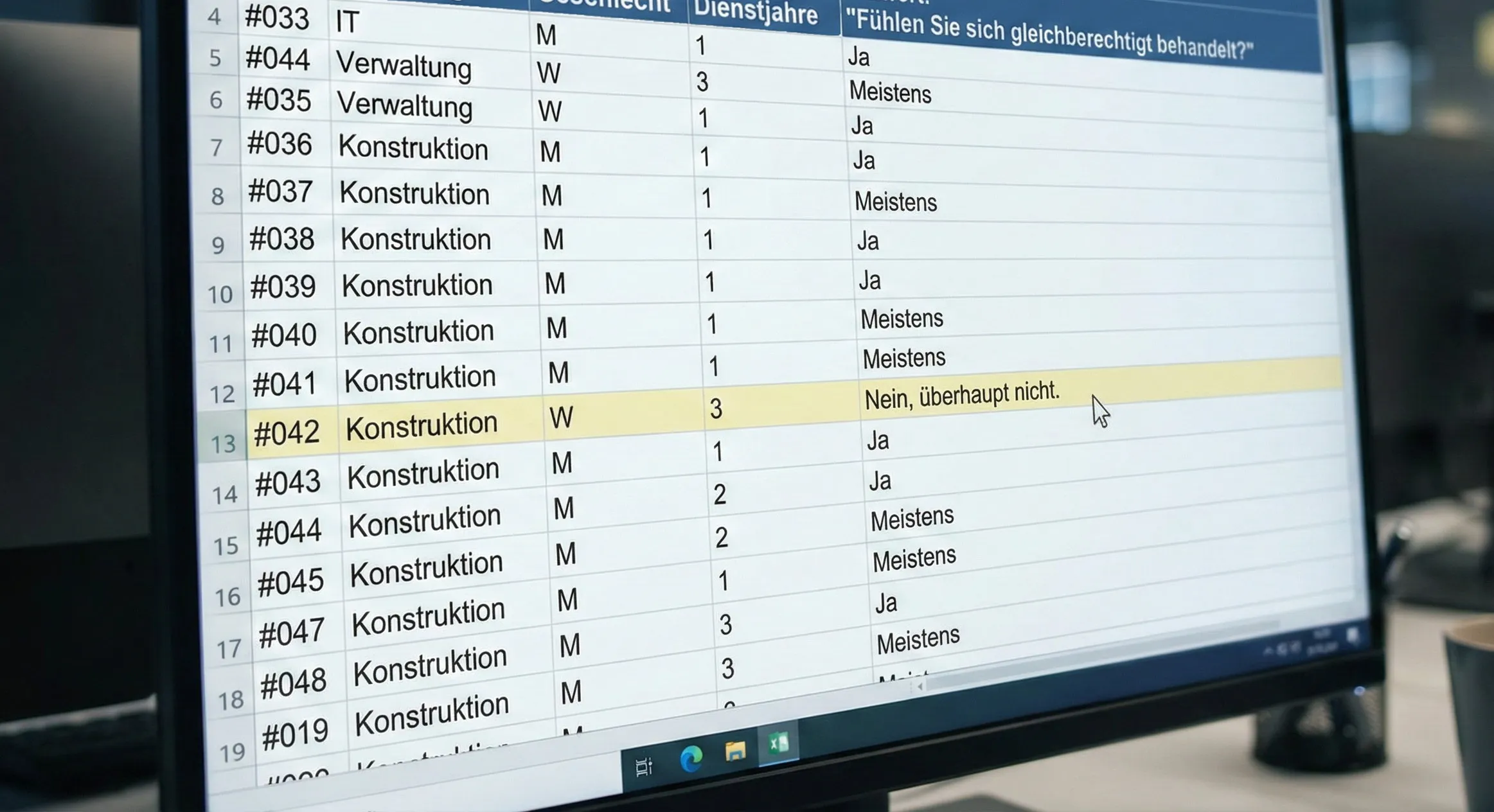
Die Illusion der Anonymität: Die Kombination aus Abteilung und Geschlecht reicht aus, um eine scheinbar vertrauliche Antwort eindeutig zuzuordnen.
Das ist kein Extremfall, denn eine Studie in Nature Communications hat gezeigt, dass 99,98 Prozent aller Personen in sogenannten anonymisierten Datensätzen re-identifiziert werden können. [1]
Die Konsequenz ist, dass Leute lügen und schweigen. Und wer nicht sicher sein kann, dass die Antwort geschützt ist, gibt die sichere Antwort statt der ehrlichen. Die Organisation trifft dann Entscheidungen auf Basis systematisch verzerrter Daten, die nicht die Realität messen, sondern das, was Leute bereit waren preiszugeben.
Das erzeugt ein Dilemma. Organisationen brauchen diese Daten für bessere Produkte und für ein Verständnis ihrer eigenen Mitarbeiter, aber herkömmliche Anonymisierung zwingt sie zu einer binären Wahl. Entweder bleiben die Daten nützlich und damit risikobehaftet, oder sie werden so stark verfremdet, dass ihr analytischer Wert verloren geht und die Umfrage entweder gefährlich transparent oder nicht verwertbar wird.
Dieses Dilemma wird seit Jahrzehnten gleich behandelt, etwa mit Richtlinien, Zugriffskontrollen und dem Versprechen, verantwortungsvoll mit den Daten umzugehen. Aber wenn dann doch Daten an die Öffentlichkeit geraten sind (zum Beispiel durch ein Leak) lässt sich nichts mehr zurücknehmen und die Versprechensgeber zucken mit den Achseln.
Aber was wäre, wenn es eine Umfrage gäbe, bei der selbst der Betreiber deine Antwort nicht lesen kann? Nicht, weil er verspricht, es nicht zu tun, sondern weil er es schlicht nicht kann. Mathematisch, strukturell, egal wie sehr er es versucht. Das ist ein anderes Versprechen als eine Datenschutzerklärung, die irgendwo als PDF liegt. Kein Vertrauen nötig, keine Richtlinie, die jemand einhalten muss. Statt Daten zu sammeln und dann (hoffentlich) zu schützen, werden sie so verarbeitet, dass sie nie in lesbarer Form existieren.
Die Technologie, die das möglich macht, heißt Secure Multi-Party Computation (kurz SMPC), und beinhaltet eine einfache Kern-Idee: Sensible Daten werden in Fragmente zerlegt und auf mehrere unabhängige Parteien verteilt. Keine dieser Parteien kann mit ihrem Fragment allein etwas anfangen, es ist ohne die anderen bedeutungslos und nicht lesbar. Wird eine Partei kompromittiert, durch einen Angriff oder einen Insider, halten die übrigen die Vertraulichkeit aufrecht. Wie ein Bankschließfach: Es gibt zwei Schlüssel, verteilt auf die Bank und die Kundin, und keiner kommt alleine rein.
Und trotzdem kann man mit diesen Fragmenten rechnen. Die beteiligten Parteien können gemeinsam Ergebnisse berechnen, zum Beispiel Durchschnitte oder Verteilungen, ohne dass die ursprünglichen Daten jemals rekonstruiert werden müssen.

Wie ein Mosaik aus Fragmenten, entsteht erst in der Aggregation das Muster
Die theoretischen Grundlagen dafür existieren seit den 1980er Jahren [2], und die Sicherheit der Protokolle ist formal bewiesen. In der Praxis hat sich SMPC trotzdem kaum durchgesetzt. Das Problem war nie die Theorie. Es ist die Umsetzung. Die Protokolle sind komplex, die bestehenden Tools sind Forschungsframeworks (MP-SPDZ, emp-tool), keine Produkte. Der Aufwand, eine SMPC-Lösung für einen konkreten Anwendungsfall zu bauen, übersteigt für die meisten Organisationen den Nutzen. Das war bei KI vor den vortrainierten Modellen nicht anders: Die Technologie ist da, aber jeder Anwendungsfall brauchte ein eigenes, teures Projekt. SMPC steckt heute in genau dieser trockenen Phase.
Was wir bauen
Wir bei utilacy haben uns vorgenommen, SMPC aus der Forschung in die Praxis zu bringen. Nicht als Framework, das andere Entwickler integrieren müssen, sondern als fertige Anwendungen, die jetzt schon mit SMPC abgesichert sind.
Das klingt einfacher als es ist. Eine SMPC-Architektur unter der Haube zu haben, bedeutet nichts, wenn die Bedienung zu aufwändig ist. Erst wenn sich das Tool anfühlt wie Google Forms, wenn Nutzer nie das Gefühl haben, mit Kryptographie zu arbeiten, ist die Umsetzung gelungen.
Umfragen sind unser erster Anwendungsfall, und wir denken, ein guter. Dafür haben wir utilacy ASK entwickelt: ein Web-Tool, mit dem man Umfragen gestaltet wie in jedem anderen Editor. Der Twist ist, dass sensible Fragen sich als versiegelt kennzeichnen lassen. Die Antworten auf versiegelte Fragen werden direkt im Browser des Teilnehmers verarbeitet. Die Rohdaten werden dabei so fragmentiert, dass sie sich nicht wiederherstellen lassen, auch nicht bei der späteren Auswertung.
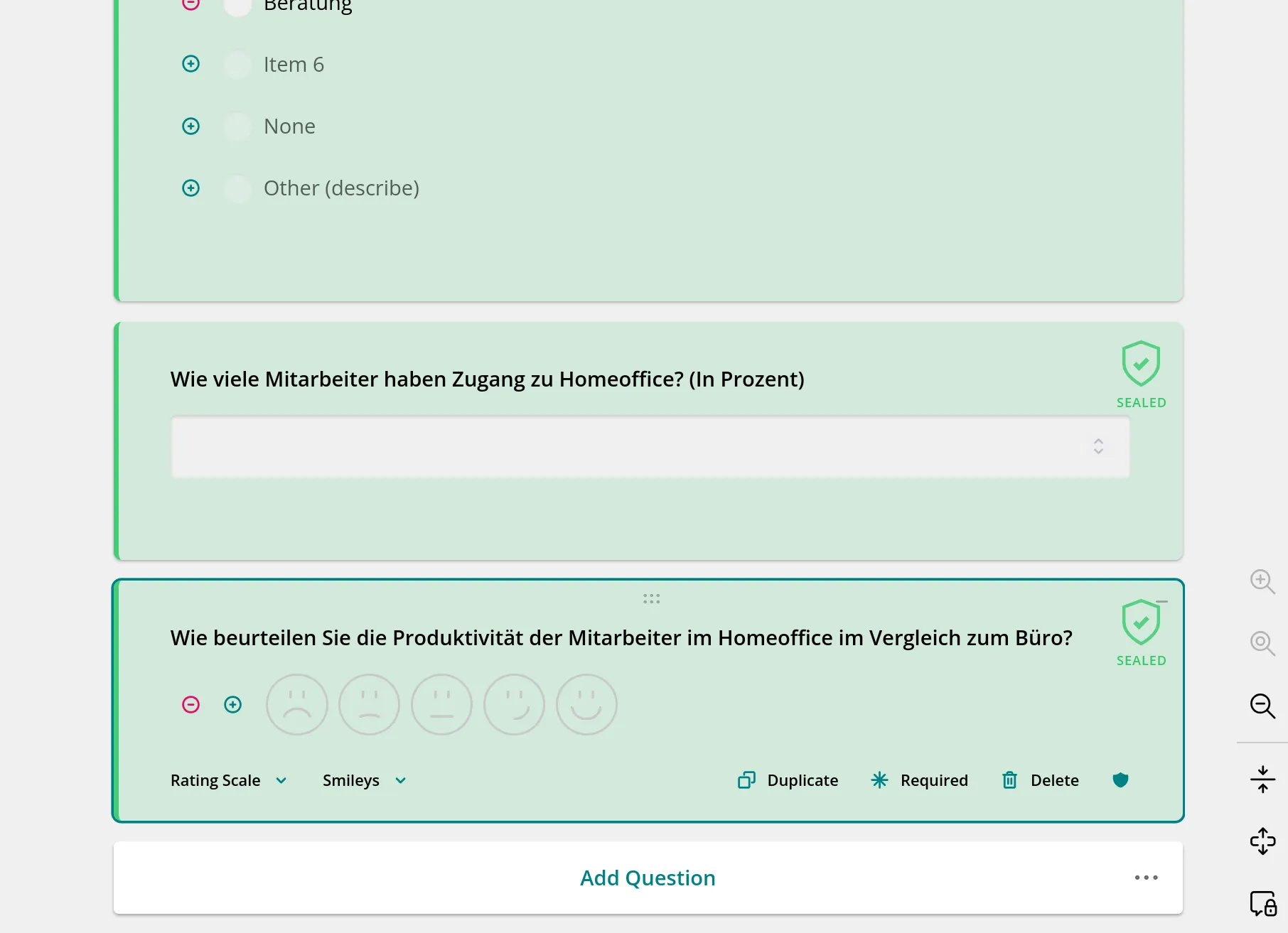
Survey-Editor mit hervorgehobener versiegelter Frage
Wer seine Umfrage fertig gestaltet hat, lädt per E-Mail-Adresse eigens bestimmte Datentreuhänder ein. Das können beliebig viele sein: utilacy als externer Partner, die HR-Abteilung, der Betriebsratsvorsitzende. Jeder Datentreuhänder hinterlegt bei Annahme einen kryptographischen Schlüssel, mit dem später die Fragmente Ende-zu-Ende verschlüsselt werden.
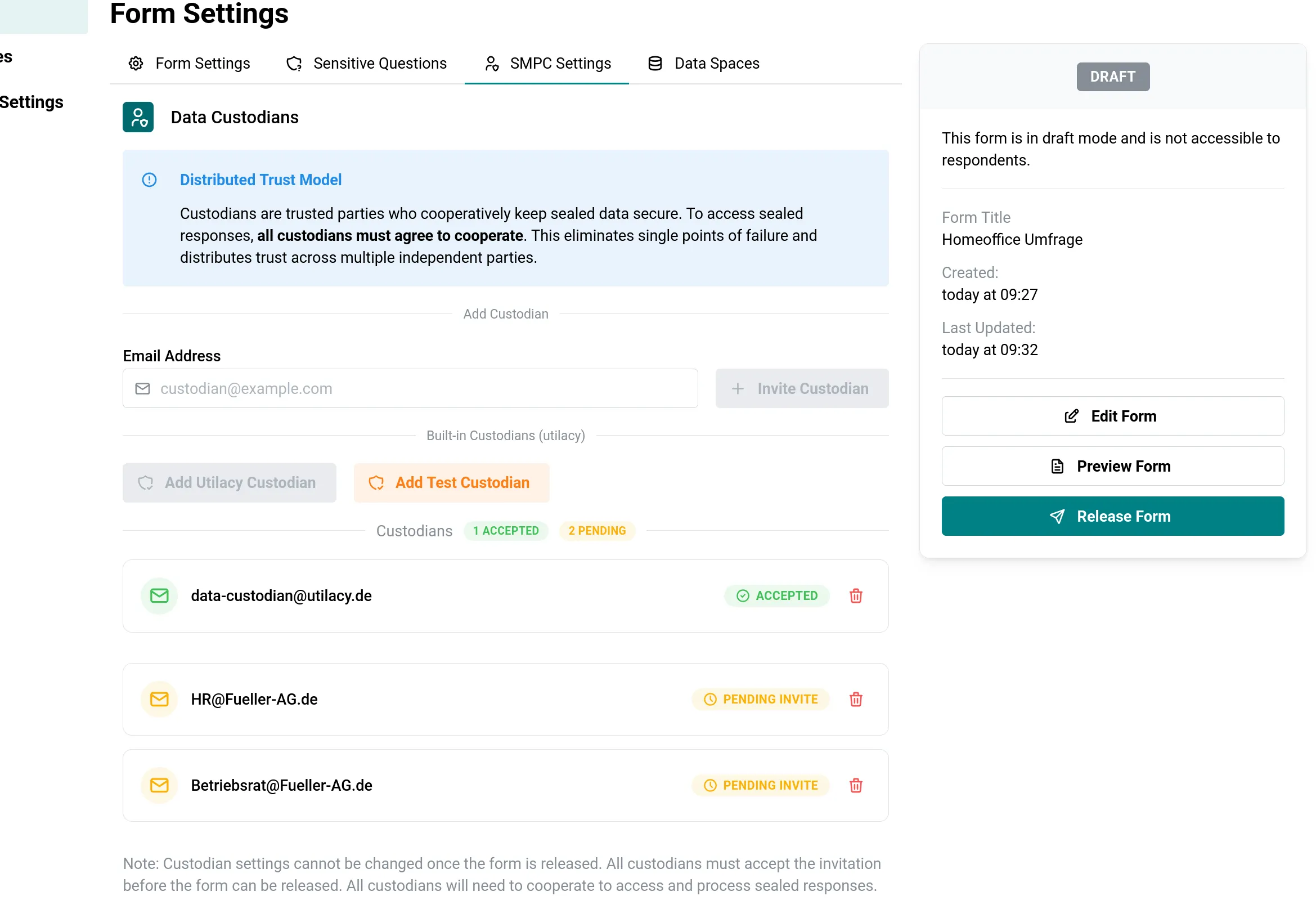
Liste der eingeladenen Datentreuhänder
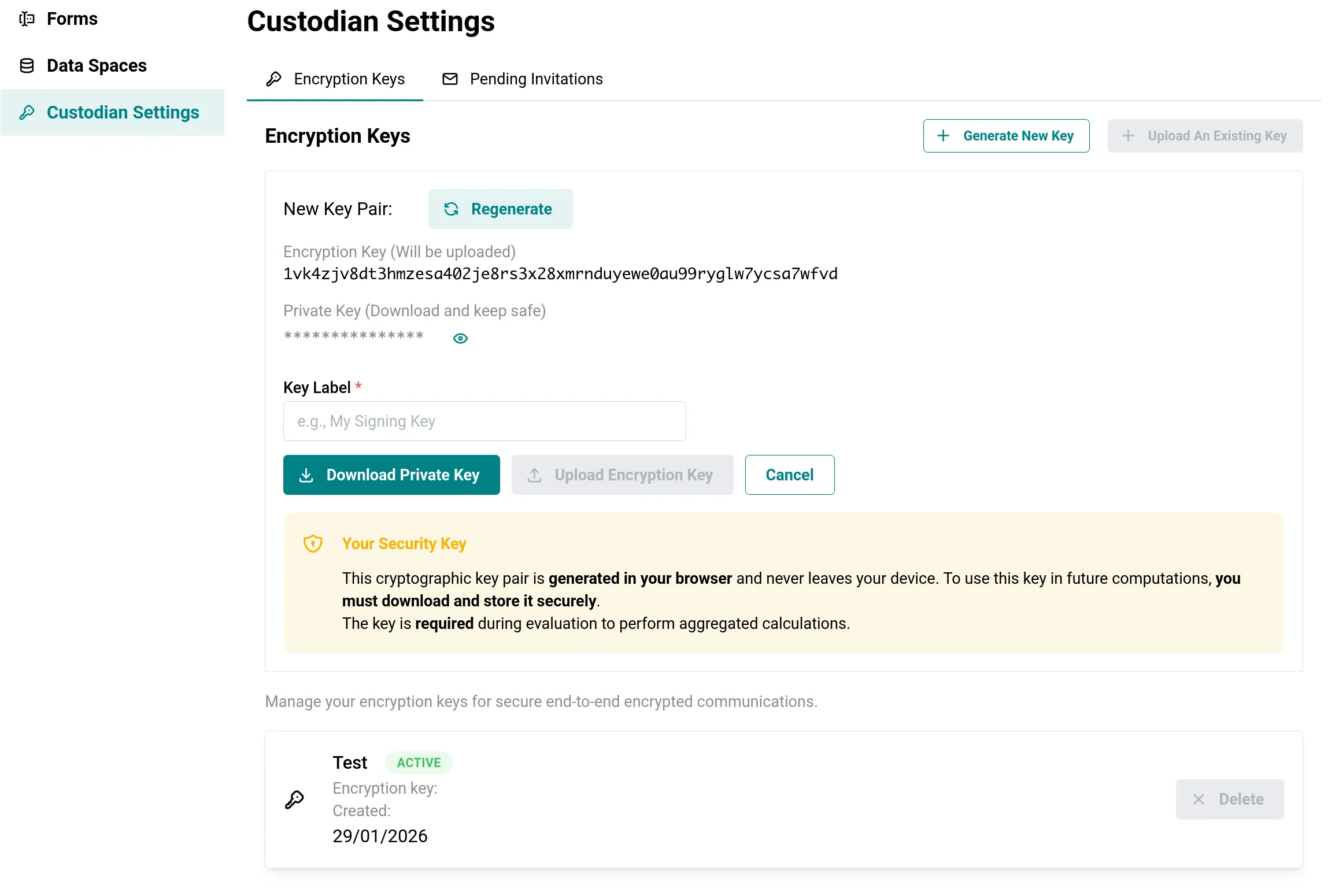
Schlüsselhinterlegung durch den Datentreuhänder
Wenn Teilnehmer die Umfrage beantworten, passiert das Entscheidende direkt im Browser: Die Antworten auf versiegelte Fragen werden noch vor dem Versand in Fragmente zerlegt und für jeden Datentreuhänder einzeln verschlüsselt. Die Fragmente landen zwar auf einem zentralen Server, wie bei jeder anderen Umfrage auch, aber sie sind dort nicht lesbar. Nicht vom Server, nicht von IT-Admins, nicht nach einem Datenleck.
Die Auswertung übernehmen die Datentreuhänder gemeinsam: Auf ihren eigenen Rechnern laufen SMPC-Server, die mit ihren jeweiligen Schlüsseln die Fragmente innerhalb des Protokolls zusammenführen und aggregieren. Am Ende steht ein aggregiertes Ergebnis (z. B. Durchschnitte, Verteilungen) ohne dass eine einzelne Antwort jemals im Klartext existiert hat.
Das Ergebnis-Dashboard: Aggregierte Auswertung ohne Zugriff auf einzelne Antworten
Warum gibt es das nicht längst?
Die Idee hinter SMPC ist nicht neu. Was fehlt, ist die Ingenieursarbeit, die aus kryptographischen Protokollen funktionierende Systeme macht.
Zwei Probleme stehen dabei im Weg.
Das erste ist Performance. SMPC-Protokolle verarbeiten Daten nicht nativ, sondern über kryptographische Protokolle in einem verteilten System, die um Größenordnungen langsamer sind als klassische Berechnungen. Wer das naiv implementiert, bekommt ein System, das zwar sicher ist, aber in der Praxis unbenutzbar. Dafür haben wir CRISPY entwickelt: ein eigenes, verteiltes Protokoll-Framework, das auf Distributed Asynchronous Deterministic Lockstepping setzt, um gleichzeitig robust, sicher und performant zu sein.
Das zweite ist Schlüsselmanagement. Damit das System funktioniert, müssen Schlüssel erzeugt, Fragmente erstellt und Daten verschlüsselt werden, und das alles im Browser des Nutzers, bevor irgendetwas den Rechner verlässt. Dafür haben wir eine Library in Rust geschrieben und als WebAssembly-Modul in den Browser eingebunden. Dieselben Operationen, Typen und Formate laufen auch im Backend, damit Verschlüsselung und Fragmentierung über das gesamte System hinweg konsistent bleiben.
Wir haben diese Probleme gelöst und mit ASK einen ersten Anwendungsfall gebaut, der Daten grundlegend anders verarbeitet als bisherige Methoden. Wer ASK benutzt, muss weder SMPC noch die dahinterliegende Kryptographie verstehen.
Unsere Vision geht über Umfragen hinaus: Wenn die Einstiegshürde für SMPC niedrig genug ist, können viele Anwendungsfälle, von Ad-Attribution bis Analytics, endlich grundlegend sicherer gelöst werden.
Lass uns reden
Du willst sehen, wie sich eine wirklich vertrauliche Umfrage anfühlt? Probier ASK aus und frag eine Demo an.
Wenn du tiefer einsteigen willst: Einen technischen Deep Dive zu unserer SMPC-Architektur veröffentlichen wir bald. Bleib dran.
Wir glauben, dass sensible Daten besser geschützt werden können, und zwar nicht durch Versprechen, sondern durch Architektur. Das hier ist erst der Anfang.

[1] Rocher, L., Hendrickx, J.M. & de Montjoye, YA. Estimating the success of re-identifications in incomplete datasets using generative models. Nat Commun 10, 3069 (2019). https://doi.org/10.1038/s41467-019-10933-3
[2] Yao, A.C. How to generate and exchange secrets. 27th Annual Symposium on Foundations of Computer Science (sfcs 1986), 162-167 (1986). https://doi.org/10.1109/SFCS.1986.25